在RISCV平台上使用匯編實現ITC FORTH的一些細節
如果你看到這篇文章,請不要過度依賴所寫的內容,
這些內容可能並不是最簡單的實現方式,也有可能有錯誤的地方,請你充分測試驗證並思考。
一些無關內容
我不是C編譯器專家
使用C實現ITC FORTH,需要注意幾個問題:
- 尾調用優化
確保你的編譯器打開了TCO
除了打開TCO,還需要驗證你的代碼是可以被編譯器優化的:
使用調試器檢查調用棧:
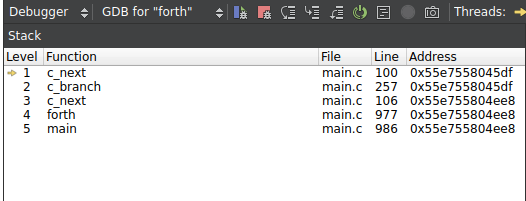
需要測試每個使用C編寫的word,確保所有C編寫的word都被尾部調用優化。
編譯器可以開啓 -fstack-usage 來生成棧使用情況的文件報告
如果函數沒有被尾調用優化,就需要檢查函數裏面是否使用棧來存放數據。
寄存器分配
RISCV的通用寄存器很多,但是需要注意有些寄存器可能會被匯編器當作特殊用途
gp 寄存器:
https://gcc.gnu.org/onlinedocs/gcc/RISC-V-Options.html#index-mrelax-6
如果要使用gp寄存器的話記得關掉relax
在使用gas的時候可以利用gcc的c預處理器功能,可以很方便的在代碼中進行寄存器重命名
gcc -x assembler-with-cpp
下面是我所用的一種寄存器分配方案, 因爲我想讓rv32e指令集的機器運行我編寫的itc forth, 所以使用的寄存器都在x0-x15之間, 如果需要優化性能,可以加上tos寄存器。
#define wp t0#define xp t1#define up tp#define ip s0#define psp sp#define rsp ra
WORD 佈局
.word link # 下一個單詞的地址.word entry # 跳轉地址,目標爲機器碼.word body # 有3種情況:# 在defcode生成的單詞中此字段沒用# 在defword生成的單詞中是單詞列表的地址,用來NEST跳轉到指定的單詞列表# 在defconst生成的單詞中作爲數據.byte attr # 單詞的屬性.byte len # 單詞名稱的長度,可以利用匯編器的機制來計算,省去手動計算.ascii "name" # 單詞名稱.p2align 2, 0 # 對齊4
NEXT 實現
a_next:lw wp, 0(ip)addi ip, ip, regsize # regsize: 4 on rv32, 8 on rv64lw xp, word_offset_entry(wp)jr xp
如果注重速度的話可以實現爲macro,如果不注重的話j a_next調用即可
NEST 實現
a_nest:rpush iplw ip, word_offset_body(wp)NEXT
UNNEST 實現
a_unnest:rpop ipNEXT
EXECUTE 實現
a_execute:dpop wplw xp, word_offset_entry(wp)jr xp
LIT 實現
a_lit:lw wp, 0(ip)addi ip, ip, regsizedpush wpNEXT
BRANCH 實現
a_branch:lw wp, 0(ip)mv ip, wpNEXT
BRANCH0 實現
a_branch0:lw wp, 0(ip)dpop xpaddi ip, ip, regsizebeqz xp, 1fNEXT1:mv ip, wpNEXT